
What is Data Engineering? Core Concepts, Tools, and Business Value

What is Data Engineering?
It focuses on the architectural foundation that enables organizations to ingest massive volumes of raw, chaotic information from distributed systems, databases, and third-party APIs. To achieve this, data engineers construct automated, fault-tolerant pipelines utilizing Extract, Transform, and Load (ETL) or Extract, Load, and Transform (ELT) methodologies. These pipelines are meticulously coded to handle continuous data streams and batch processes, ensuring high throughput and low latency across complex hybrid and cloud-native computing environments.
Once extracted, this raw data undergoes rigorous computational transformation where programmatic rules are applied to cleanse anomalies, standardize conflicting formats, enforce schema validation, and join disparate datasets. The refined, structurally consistent data is then securely loaded into highly optimized storage repositories, such as data warehouses and data lakes, utilizing advanced storage formats and clustered indexing for rapid querying. Ultimately, the primary objective of data engineering is to establish a centralized, reliable, and query-ready environment. This meticulously governed architecture eliminates data silos and provides the essential, high-quality foundation required for business intelligence, real-time operational analytics, and complex machine learning workloads.
The Problem with Raw Data
Why is this massive infrastructure necessary? Because data rarely originates in a neat, organized spreadsheet. A retail company might have customer names in a cloud-based CRM, inventory numbers in a legacy on-premise database, and user behavior tracking in raw JSON files generated by their mobile app.
If the CEO wants a report on how mobile app usage affects inventory turnover, someone has to connect those three entirely different systems. The data engineer builds automated software that reaches into these diverse sources, translates them into a common language, corrects the inevitable errors (such as missing zip codes or duplicate names), and unifies them into a single, cohesive ecosystem.
The Anatomy of a Pipeline: What is Data Engineering Doing in the ETL Process?
The heart of this profession revolves around moving information from point A to point B. This journey is managed by automated software pathways known as "data pipelines." The most famous framework for these pipelines is the ETL process.
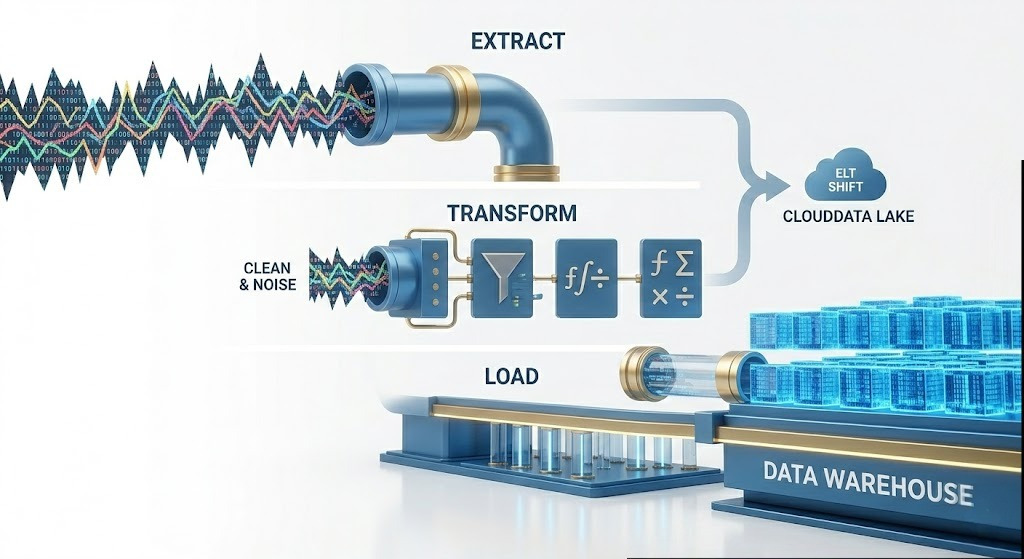
1. Extract: Gathering the Raw Materials
The first step is pulling the information from its various origins. This must be done carefully. If a data engineer pulls too much information from the company’s main sales database during peak shopping hours, the entire website could crash. Engineering the extraction phase means writing highly efficient code that captures only the newly generated information (often called incremental loading) without disrupting the systems that are actively running the business.
2. Transform: The Heavy Lifting
This is where the true value is added. Raw information is incredibly messy. The transformation phase applies a strict set of business rules to cleanse the data. For instance, if an e-commerce platform operates globally, the pipeline might need to convert all sales figures from Euros, Yen, and Pounds into US Dollars in real-time based on the daily exchange rate. It might also involve masking sensitive information, such as replacing a customer's full credit card number with just the last four digits to maintain strict privacy compliance.
3. Load: Delivering to the Destination
Once the information is standardized and cleaned, it must be stored in a permanent location optimized for analysis. Engineers load this refined product into a centralized repository, typically a Data Warehouse.
(A vital modern shift: As cloud computing has become exponentially more powerful, many companies have shifted from ETL to ELT—Extract, Load, Transform. They load the raw data directly into a massive cloud database and use the cloud's infinite computing power to transform the data after it has already arrived.)
The Holy Trinity of Data Roles: Engineer, Scientist, and Analyst
To fully grasp the landscape, you must understand how different roles collaborate. The tech industry often conflates these titles, but they represent entirely different skill sets.
Data Engineer (The Builder) | Architecture & Pipelines | Uptime, Speed, Reliability | Python, SQL, Spark, Airflow |
Data Scientist (The Innovator) | Prediction & Algorithms | Model Accuracy | Math, Statistics, Machine Learning |
Data Analyst (The Storyteller) | Historical Reporting | Business Insights S | SQL, Visualization Tools |
The Hierarchy of Needs: What is Data Engineering Doing for AI
There is a famous concept in the tech world known as the "AI Hierarchy of Needs." At the very top of the pyramid is Artificial Intelligence and Deep Learning. But what forms the wide, heavy base of that pyramid? Data collection, storage, and pipeline infrastructure.
You cannot build a smart AI model without a massive volume of perfectly organized training data. Companies that try to hire brilliant data scientists before they hire data engineers often find their scientists spending 80% of their time just trying to manually clean up spreadsheets. The engineer provides the high-octane fuel that makes advanced data science possible.
The Essential Toolkit: How the Infrastructure is Built
The technology stack used to build these systems is vast and constantly evolving. While the foundational concepts remain steady, the tools are highly specialized.
- Programming Languages: Python and SQL are the absolute bedrock of the profession. Python is used to write complex automation scripts, while SQL is the universal language used to communicate with databases. For exceptionally large, high speed systems, languages like Java or Scala are frequently employed.
- Storage Solutions: Engineers must choose where the data lives. They build Data Lakes (vast, cheap storage for raw, unstructured files) and Data Warehouses (highly structured, heavily indexed databases designed specifically for complex analytical queries).
- Processing Frameworks: When dealing with "Big Data" (datasets so large they cannot fit on a single computer), engineers use distributed computing frameworks like Apache Spark. Spark allows them to split a massive processing job across hundreds of different computers simultaneously, turning a task that would take days into one that takes minutes.
- Orchestration: Imagine a symphony orchestra with no conductor. It would be chaos. In the digital world, tools like Apache Airflow act as the conductor. Airflow ensures that the thousands of automated tasks run in the exact right order, pausing the pipeline and sending alerts if a critical error occurs.
Real-World Impact: How the Foundation Drives Modern Business
It is easy to get lost in the technical jargon, but the impact of this engineering is felt by consumers every single day.
- Data Engineering for E-Commerce and Personalization: When you visit a major online retailer and see a section labeled "Customers who bought this also bought," you are looking at the end result of exceptional data engineering. A pipeline is continuously tracking every click, purchase, and search term from millions of users, cleaning that data, and feeding it into a recommendation engine in milliseconds.
- Data Engineering in Streaming Entertainment: Global video streaming platforms rely heavily on this infrastructure to manage the massive amounts of bandwidth and user preferences. When millions of people log on simultaneously to watch a highly anticipated season finale, behind-the-scenes pipelines are analyzing viewing habits, buffering rates, and server loads to ensure the video plays smoothly without crashing the platform.
- Financial Services and Fraud Detection: When you swipe your credit card in a foreign country, the bank decides whether to approve or decline the transaction in less than a second. This is only possible because a highly optimized stream-processing pipeline is instantly cross-referencing your transaction against years of your historical spending data and global fraud patterns.
The Future of the Discipline
As we look ahead, the field is evolving rapidly. We are seeing a massive shift toward "real-time streaming." Historically, companies processed their data in overnight batches. Today, businesses demand to know what is happening the very second it occurs.
Furthermore, as organizations grow, centralized data engineering teams often become a bottleneck. The industry is moving toward a decentralized "Data Mesh" approach. Instead of one team handling all the pipelines for the whole company, individual departments (like HR, Marketing, and Sales) are given the automated tools and guardrails to build and manage their own data products safely.
Frequently Asked Questions (FAQ)
It is the "plumbing" of the tech world—the specialized practice of building the infrastructure and pipelines that collect, clean, and store raw data so it can be used for analysis.
Engineers are the builders who create the "pipes" and infrastructure; Scientists are the innovators who use that data to build predictive models and find insights.
ETL cleans data before it is stored; ELT loads it raw and cleans it after it arrives, utilizing the massive processing power of modern cloud warehouses.
AI is only as good as its data. Engineers provide the clean, organized "fuel" that makes machine learning and deep learning possible.
Conclusion: The Backbone of the Digital Economy
Ultimately, data engineering serves as the unseen engine powering the modern digital economy. While generative AI and sleek executive dashboards often steal the spotlight, those innovations simply cannot function without the robust pipelines and processing frameworks built behind the scenes. It is a discipline defined by rigorous problem-solving, deep architectural planning, and an unwavering dedication to operational reliability.
As the global appetite for information continues to explode, maintaining a rock-solid, scalable foundation is critical for any organization looking to compete. You don't have to tackle this complex digital plumbing alone; our team is here to help you design, automate, and scale the perfect data architecture to power your analytics and long-term success.
Blogs














Office Location
5th Floor, 1174, 24th Main Rd 2nd Sector,
Garden Layout, Sector 2, HSR Layout, Bengaluru,
Karnataka 560102
Email Us: info@as13.ai
Follow Us

Roles
AI
Cyber Security
