
Serverless Architecture Explained: The Event-Driven Future of Cloud Computing

Serverless architecture is a cloud execution model that allows developers to build and run applications without managing the underlying infrastructure. It is a paradigm shift that transforms how we deploy code, moving the focus entirely from server maintenance to product innovation.
If you’ve ever woken up at 3 AM to restart a crashed virtual machine, or spent a Friday evening patching a Linux kernel just to keep a simple API running, you understand the operational pain that serverless aims to cure.
But beyond the buzzwords and marketing fluff, what does a production-ready serverless system actually look like in 2026? It is not just "no servers," it is a fundamental rethink of distributed system design. Let's break down the abstraction layers and examine the nuts and bolts of building event-driven systems at scale.
What Actually is "Serverless"?
Despite the confusing name, there are still servers definitely involved. The difference is that the cloud provider abstracts them away completely. You do not patch the OS, you do not provision RAM for idle time, and you do not manage auto-scaling groups or load balancers.
At a technical level, Serverless is defined by four key tenets that differentiate it from traditional IaaS (Infrastructure-as-a Service) or PaaS (Platform-as-a-Service):
- No Server Management: The "Control Plane" (provisioning, patching, securing the host) is fully managed by the vendor.
- Auto-scaling: The "Data Plane" scales linearly and automatically with traffic, all the way down to zero when idle.
- Pay-for-Value: You are charged based on execution duration (often in 1ms increments) and memory configured, not for reserved capacity.
- Implicit High Availability: Fault tolerance is built in by default across multiple Availability Zones (AZs).
This ecosystem splits into two main camps that work together:
- FaaS (Function-as-a-Service): The compute layer (e.g., AWS Lambda, Google Cloud Functions, Azure Functions). You upload discrete chunks of code that run in ephemeral environments in response to events.
- BaaS (Backend-as-a-Service): Managed third-party services that handle state and logic. If you are managing your own MongoDB cluster on EC2, you aren't fully serverless. True serverless uses managed services like Amazon DynamoDB for data, Auth0/Cognito for identity, or S3 for storage.
The Architectural Shift:
In a traditional app, your code is a monolith handling everything. In a serverless app, your logic is "glue code" living in FaaS, connecting various BaaS components.
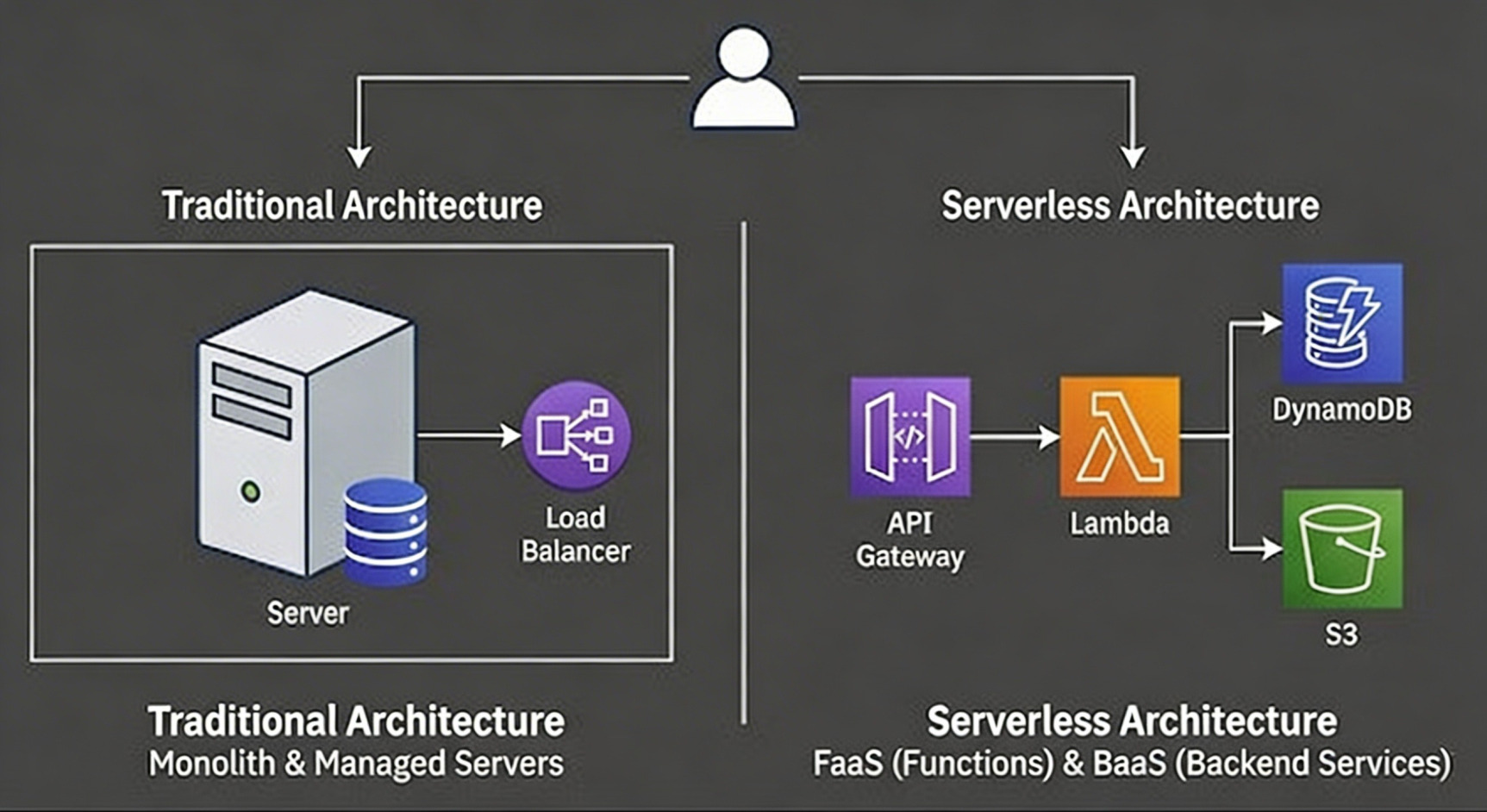
The evolution from monolithic server management to composed, managed services.
Under the Hood: How FaaS Actually Works
When a trigger fires (e.g., an incoming HTTP request or an S3 file upload), the cloud provider doesn't just instantly "run code." There is a complex orchestration happening in milliseconds.
It's important to understand that FaaS functions don't typically run in standard Docker containers. They run in specialized, lightweight MicroVMs (like AWS Firecracker or Google's gVisor). These technologies provide the hardware virtualization-level isolation needed for multi-tenant security, but with startup times measured in milliseconds rather than seconds.
The lifecycle of a request looks like this:
- Placement: The control plane receives the event and selects an available worker node in the fleet.
- Isolation: A secure MicroVM is spun up (or reused).
- Bootstrap: The language runtime (Node.js, Python, Go, Java) is initialized within the MicroVM.
- Execution: Your function handler code is finally invoked to process the event.
This entire process is invisible to you, but understanding it is crucial for optimizing performance, specifically regarding "Cold Starts.
The Event-Driven Paradigm Shift & Cost Model
Serverless is inherently event-driven. Nothing happens until an event triggers it. This is massive. Traditional microservices are "always-on," listening on a port and burning money even when no one is using them. Serverless functions sleep until needed.
The cost model is revolutionarily granular, shifting financial risk from the user to the provider:
$$Cost = (\text{Total Invocations}) \times (\text{Duration in ms}) \times (\text{Memory Allocated GB})$$
If your API gets zero traffic at night, your compute cost is exactly $0.00.
Essential Serverless Design Patterns for Scale
You cannot simply copy-paste a monolithic codebase into a Lambda function (a patterns known as the "Lambdalith") and expect magic. You need specific distributed patterns to handle scale and ensure reliability.
1. The Fan-Out / Fan-In Pattern
Serial processing is the enemy of serverless efficiency. If a user uploads a massive CSV file, don't process it row-by-row in one long-running function that might time out.
- The Pattern: An S3 upload triggers an initial "Dispatcher" Lambda. This Lambda splits the CSV into chunks and publishes messages to an SNS topic or EventBridge. This triggers dozens of "Worker" Lambdas simultaneously to process chunks in parallel.
- Result: A 60-minute serial job finishes in 2 minutes.
2. Queue-Based Load Leveling
Serverless functions scale almost instantly. Your downstream relational database (like PostgreSQL or MySQL) does not. If 10,000 users hit your API at once, 10,000 Lambdas will spin up and try to open connections to your database, potentially crashing it.
- The Fix: Put a Queue (SQS) between the API Gateway/Lambda and the Database. The queue acts as a buffer, absorbing the spike. A separate, throttled Lambda function pulls messages from the queue at a rate the database can comfortably handle.
Technical Deep Dive: The "Cold Start" & Optimization
If you are building serverless, you will encounter the Cold Start. This is the latency incurred when a new execution environment must be spun up from scratch because no idle environments are available.
The latency formula looks roughly like this:
$$Latency = \text{Code Download} + \text{MicroVM Start} + \text{Runtime Init} + \text{User Code Init}$$
Production-Grade Optimizations for 2026:
- Provisioned Concurrency: The easiest fix. You pay the provider to keep a set number of environments "warm" and ready to respond in double-digit milliseconds. Crucial for strict SLAs.
-
Optimize Dependencies (Tree Shaking): Don't import the entire AWS SDK if you only need S3 client. Use modular imports (e.g., @aws-sdk/client-s3 ) to keep your deployment package small, speeding up the "Code Download" phase.
-
TCP Keep-Alive & Connection Reuse: In your code, initialize database connections outside the function handler. The container freezes between invocations, but the memory state is preserved for subsequent "warm" starts.
Node.js Example of Connection Reuse:
// Initialize outside the handler looplet dbConnection = null;
exports.handler = async (event) => {
// Only connect if a connection doesn't already exist within this container if (!dbConnection) {
console.log("Cold Start: Initializing DB connection...");
dbConnection = await connectToDatabase();
} else {
console.log("Warm Start: Reusing existing connection."); }
// execute your logic using dbConnectionconst result = await dbConnection.query('SELECT * FROM
items');
return result;
};
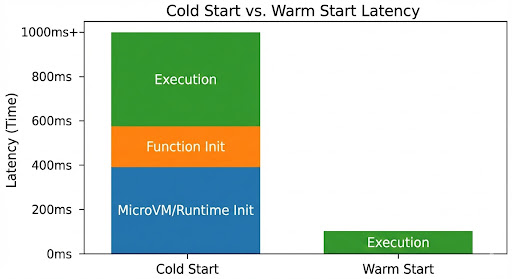
The significant latency difference between a fresh environment boot and reusing an existing one
The "Distributed System Tax": Challenges to Accept
Serverless isn't a free lunch. You trade infrastructure management for application complexity.
1. The Challenge of Observability
Debugging a monolith is like finding a broken wire in a single box. Debugging serverless is like finding which of 50 different tiny boxes lost the message. Because requests jump from API Gateway $\rightarrow$ Lambda $\rightarrow$ SQS $\rightarrow$ Lambda $\rightarrow$ DynamoDB, standard logging isn't enough.
Distributed Tracing is Mandatory: You must use tools like AWS X-Ray, Honeycomb, or OpenTelemetry. These generate a unique "Trace ID" that follows the request across service boundaries, allowing you to visualize the entire path as a waterfall graph and pinpoint bottlenecks.
2. Security requires "Least Privilege."
In a monolith, the server often has broad network access. In Serverless, security is granular. Every single function should have its own unique IAM (Identity and Access Management) Role.
The "Image Resizer" function should only have permission to read from the source bucket and write to the destination bucket. It should absolutely not have permissions to read from the "User Profiles" DynamoDB table. This drastically limits the "blast radius" if a function's code is compromised.
Serverless (FaaS) vs. Containers (Kubernetes)
The line is blurring, but the distinction still matters for architectural decisions.
Abstraction Level | Code / Functions | Containers / PodsCourses |
Scaling Speed | Milliseconds (Event driven spikes) | Seconds/Minutes (Metric-driven) |
State | Purely Stateless | Can be Stateful or Stateless |
Max Execution Time | Hard limits (e.g., 15 mins on AWS) | Unlimited |
Cost Model | Pay per request/GB second | Pay for running underlying instances |
Ideal Use Case | APIs, Event processing, Glue code | Long-running tasks, legacy migration |
Frequently Asked Questions (FAQ)
Serverless lets you run code without managing servers. The cloud provider handles scaling, patching, and availability automatically.
A cold start is the extra delay when a new function environment is created before running your code.
Fan-out processing, queue-based buffering (SQS), and event-driven workflows are the most common patterns for production.
Serverless is best for APIs and event processing. Kubernetes is better for long-running and always-on workloads.
Conclusion: Intelligent Management Is the New Advantage
Serverless architecture is not a silver bullet for every problem, but it is arguably the most efficient way to build scalable, modern applications in 2026. It forces you to design systems that are decoupled and event-driven by default.
While it introduces complexity in debugging and requires learning new patterns, the ability to ship a globally available, production-ready API in an afternoon without touching a single server configuration file is a superpower in the modern tech landscape. It's time to stop managing servers and start shipping code.
Blogs















Office Location
5th Floor, 1174, 24th Main Rd 2nd Sector,
Garden Layout, Sector 2, HSR Layout, Bengaluru,
Karnataka 560102
Email Us: info@as13.ai
Follow Us

Roles
AI
Cyber Security
